



Introduction
Back then (up until now, maybe) we used to download videos and convert them into mp3 formats for our custom playlist. By providing URLs and dealing lots of pop-up ads on clicking the wrong download button made us satisfied and we were abled to complete our old-school playlists.
Last year, because of being bored and had an eagerness to practice my skills with AWS Serverless Technology, I decided to create my own YouTube Video Downloader. By leveraging the use of a useful npm package, it should be fairly easy to create one. The setup for the application should be cheap in price but truly functional.
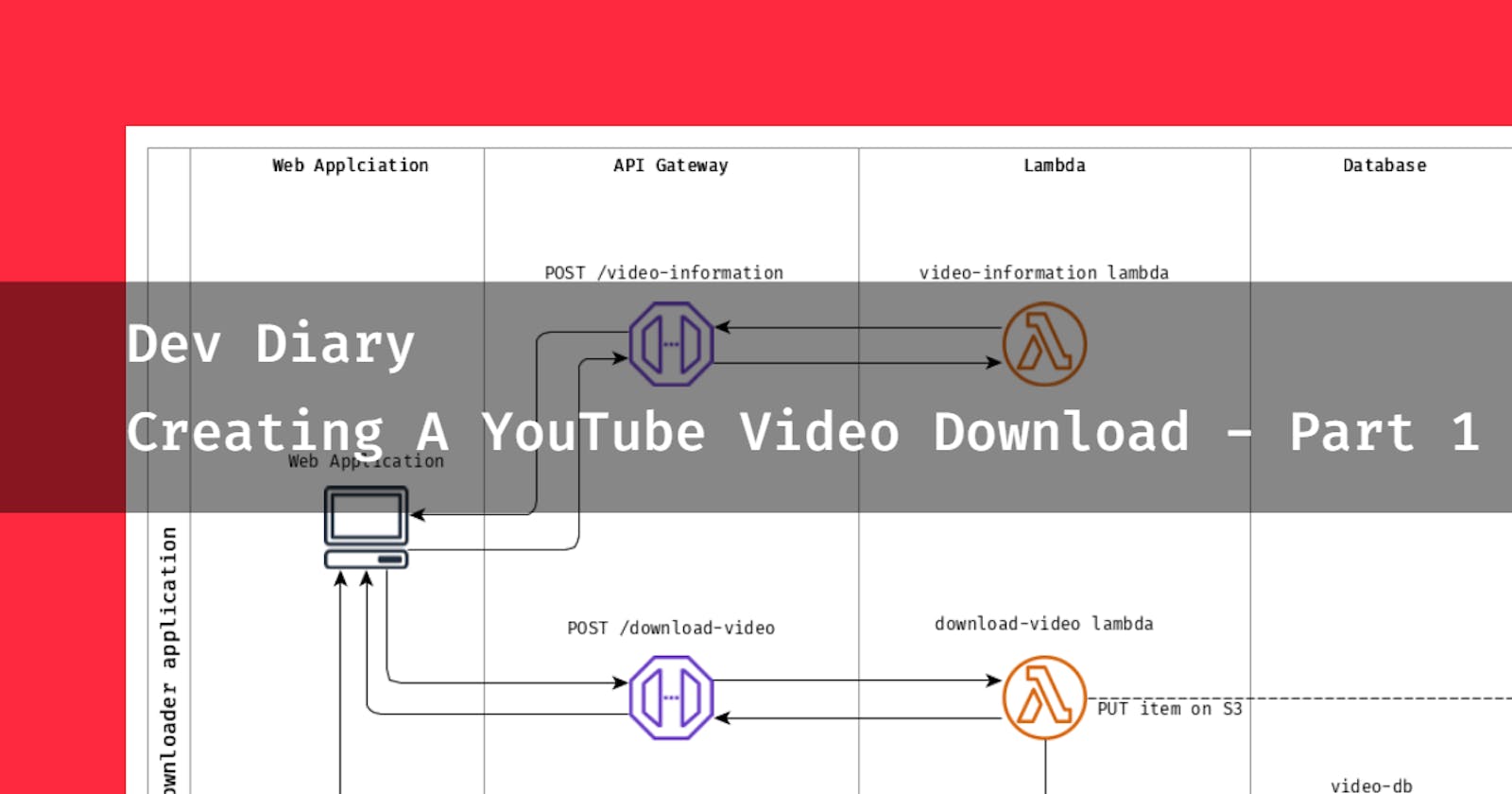
In order to visualize the basic flow of the whole application - I'll explain the diagram below:

We have 5 layers to describe:
- The
web applicationlayer that includes mobile and browser app. API EndpointsLamdas- Handlers for REST endpoints
- And a single lambda for CRON job
- Database - on this project I used
DynamoDB - Storage - an
S3bucket where we will put the videos for download.
Web Application
I used the following:
- Angular (v10.1.1) - I personally love to try the
@anotationwith typescript. - Akita Framework - For simple state management.
API Gateway
There are only two endpoints that I used for this project. And both of them are scraping youtube video's data.
Lambdas
To handle the said two endpoint, I created two lambdas. These two lambdas uses the ytdl-core npm library.
video-information lambda will scrape the meta data from youtube, including the video's title, description, and thumbnail.
download-video lambda will download the video from youtube then it will create a write stream for saving it to S3. Then after it saves to S3, it will insert a new record to the database. And after that, it will return the exact location / key on the S3 as a download URL referrence.
The other lambda - delete-video is triggered via Cloudwatch event CRON and by DELETE events on the database. I know it's weird why it needs to listen two different sources, but I encountered a weird behavior on dynamodb where a record has a ttl but it didn't trigger the lambda. So I set it up to run on first thing in the morning to delete 2 days old videos on S3.
Database
For this project I used DynamoDB, since I only need to store 2 fields on the table.
{
ttl: DateTime,
location: string
}
We set a ttl value so a record will be automatically deleted and it will also trigger the delete-video lambda.
Storage
For simplier implementation - I choose S3 as a storage for downloaded videos.
So that's it for a simple overview of my simple youtube video application.